%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Generative Model
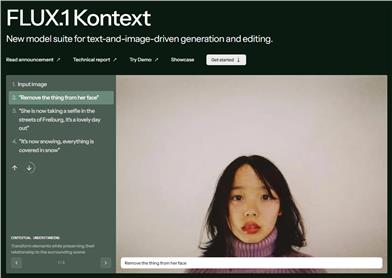
FLUX.1 Context
FLUX.1 Context is the latest image generation and editing model from Black Forest Labs, which combines text and image inputs to enable flexible image modifications. The model significantly enhances design and creative workflows with its fast inference speed and high-quality image generation. Its key advantage lies in supporting context-based image generation and editing, applicable to various scenarios such as concept design and sketch creation. FLUX.1 Context offers multiple versions, including quick editing and high-performance options, aimed at serving various creative professionals and developers.
Image Editing
38.1K

Liquid
Liquid is an autoregressive generative model that facilitates seamless integration of visual understanding and text generation by decomposing images into discrete codes and sharing feature space with text tokens. The main advantage of this model is the elimination of the need for externally pre-trained visual embeddings, reducing resource dependence, while simultaneously discovering a synergistic effect between understanding and generation tasks through the law of scaling.
Image Generation
40.6K

UNO
UNO is a multi-image conditional generation model based on diffusion transformers. By introducing progressive cross-modal alignment and universal rotational positional embedding, it achieves highly consistent image generation. Its main advantages lie in enhanced controllability over the generation of single or multiple subjects, making it suitable for various creative image generation tasks.
Image Generation
41.4K

Easycontrol
EasyControl is a framework that provides efficient and flexible control for Diffusion Transformer (DiT), aiming to solve the efficiency bottlenecks and lack of model adaptability in the current DiT ecosystem. Its main advantages include: supporting multiple conditional combinations, improving generation flexibility and inference efficiency. This product is developed based on the latest research results and is suitable for use in image generation, style transfer, and other fields.
AI Model
38.4K
IMM
Inductive Moment Matching (IMM) is an advanced generative model technology primarily used for high-quality image generation. This technology, through an innovative inductive moment matching method, significantly improves the quality and diversity of generated images. Its main advantages include efficiency, flexibility, and robust modeling capabilities for complex data distributions. IMM was developed by Luma AI and a research team at Stanford University, aiming to advance the field of generative models and provide powerful technical support for applications such as image generation, data augmentation, and creative design. This project open-sources the code and pre-trained models, facilitating quick adoption and application by researchers and developers.
Image Generation
72.6K
MIDI
MIDI is an innovative image-to-3D scene generation technology that utilizes a multi-instance diffusion model to directly generate multiple 3D instances with accurate spatial relationships from a single image. The core of this technology lies in its multi-instance attention mechanism, which effectively captures inter-object interactions and spatial consistency without complex multi-step processing. MIDI excels in image-to-scene generation, suitable for synthetic data, real-world scene data, and stylized scene images generated by text-to-image diffusion models. Its main advantages include efficiency, high fidelity, and strong generalization ability.
3D modeling
64.9K

SRM
SRM is a spatial reasoning framework based on a denoising generative model, used for inference tasks on sets of continuous variables. It gradually infers the continuous representation of these variables by assigning an independent noise level to each unobserved variable. This technique excels in handling complex distributions and effectively reduces hallucinations during the generation process. SRM demonstrates for the first time that denoising networks can predict the generation order, thus significantly improving the accuracy of specific inference tasks. The model was developed by the Max Planck Institute for Informatics in Germany and aims to advance research in spatial reasoning and generative models.
Model Training and Deployment
46.6K
Microsoft Muse
Muse is a generative AI model developed by the Microsoft research team in collaboration with Xbox Games Studios, designed to support game ideation. Trained on a large-scale dataset of human gameplay, it can generate coherent game visual and action sequences. This technology showcases the potential of AI in game design, providing new creative approaches and experiences for future game development.
Game Production
52.2K
Bioemu
BioEmu, developed by Microsoft, is a deep learning model for simulating the equilibrium ensembles of proteins. This technology uses a generative deep learning approach to efficiently generate protein structure samples, helping researchers better understand the dynamic behavior and structural diversity of proteins. The key advantages of this model are its scalability and efficiency, allowing it to handle complex biomolecular systems. It is suitable for research in areas such as biochemistry, structural biology, and drug design, providing scientists with a powerful tool for exploring the dynamic properties of proteins.
Research Equipment
53.8K
Stable Diffusion 3.5 Medium
Stable Diffusion 3.5 Medium is a text-to-image generation model developed by Stability AI, featuring improved image quality, typography, understanding of complex prompts, and resource efficiency. The model employs three fixed pre-trained text encoders, enhances training stability using QK normalization, and incorporates dual attention blocks in the first 12 transformer layers. It excels in multi-resolution image generation, consistency, and adaptability across various text-to-image tasks.
Image Generation
65.1K
Auraflow
AuraFlow v0.1 is a fully open-source, streaming-based text-to-image generation model that achieves state-of-the-art results on GenEval. Currently in the beta stage, the model is continuously improving with invaluable community feedback. We thank two engineers, @cloneofsimo and @isidentical, for making this project a reality and the researchers who laid the groundwork for it.
AI Image Generation
93.6K
English Picks

PROTEUS
PROTEUS is a next-generation foundational model launched by Apparate Labs, designed for real-time expression generation in humanoids. It utilizes an advanced transformer-based latent diffusion model, with an innovative latent space design that achieves real-time efficiency. With further architectural and algorithmic refinements, it can reach over 100 frames per second video streaming. PROTEUS aims to provide a visual embodiment through voice control, offering an intuitive interface for artificial conversational agents, and is compatible with various large language models, allowing for customization for a diverse range of applications.
AI Color Generation
51.3K
Fresh Picks

PCM
Phased Consistency Model (PCM) is a novel generative model designed to address the limitations of Latent Consistency Model (LCM) in text-conditioned high-resolution generation. PCM improves generation quality throughout training and inference stages using innovative strategies, and its effectiveness in combination with Stable Diffusion and Stable Diffusion XL base models has been validated through extensive experiments at various steps (1, 2, 4, 8, 16).
AI Image Generation
88.6K
Imagen 3 By Google
Imagen 3 is our highest-quality text-to-image model, capable of generating images with better details, richer lighting, and fewer artifacts. Through improved text understanding capabilities, Imagen 3 can generate images in various visual styles and capture subtle details in long-text prompts. Imagen 3 can be used for tasks ranging from generating quick sketches to high-resolution images, and offers multiple optimized versions.
AI image generation
56.0K
Lumina T2X
Lumina-T2X is an advanced text-to-any-modal generation framework that can convert text descriptions into vivid images, dynamic videos, detailed multi-view 3D images, and synthetic speech. The framework employs a stream-based large diffusion transformer (Flag-DiT) architecture, supports models up to 700 million parameters, and can extend sequence lengths to 128,000 tokens. Lumina-T2X integrates image, video, 3D object multi-view, and audio spectrum into a unified spatiotemporal latent token space, enabling the generation of outputs of any resolution, aspect ratio, and duration.
AI image generation
61.0K
Unifl
UniFL is a project designed to enhance the quality of generative models and accelerate inference speeds. It effectively addresses the existing issues of image quality, aesthetic appeal, and inference speed in current diffusion models through three key components: perceptual feedback learning, decoupled feedback learning, and adversarial feedback learning. Through experimental validation and user studies, UniFL has demonstrated significant performance improvements and strong generalization capabilities across multiple diffusion models.
AI image generation
44.7K
Mistral 7B Instruct V0.2
Mistral-7B-Instruct-v0.2 is a large language model fine-tuned with instructions based on the Mistral-7B-v0.2 model. It features a 32k context window and a 1e6 Rope Theta value. The model can generate corresponding text outputs according to given instructions, supporting various tasks such as Q&A, writing, and translation. Through instruction-tuning, the model can better understand and execute instructions. Although the model currently lacks a targeted review mechanism, it will continue to be optimized to support deployment in more scenarios.
AI Model
81.4K
Command R
Command-R is a scalable generative model that balances high efficiency and strong accuracy, empowering enterprises to move beyond the proof-of-concept stage and into production. Designed for long-form tasks, it excels in retrieval-augmented generation with external APIs and tools. Command-R works in tandem with Cohere's Embed and Rerank models to provide first-class integration for RAG applications and delivers outstanding performance in enterprise use cases.
AI Content Generation
96.9K
Trajectory Consistency Distillation (TCD)
TCD is a consistency distillation technique for text-to-image synthesis that leverages a Trajectory Consistency Function (TCF) and strategic random sampling (SSS) to reduce errors during the synthesis process. TCD significantly improves image quality at low NFE (noise-free energy) and maintains more detailed results than the teacher model at high NFE. TCD achieves superior generation quality at both low and high NFE without requiring additional discriminator or LPIPS supervision.
AI image generation
71.8K
Stable Video Diffusion 1.1 Image To Video
Stable Video Diffusion (SVD) 1.1 Image-to-Video is a diffusion model that generates videos corresponding to static images as conditioning frames. This latent diffusion model is trained to generate short video clips from images. At a resolution of 1024x576, the model is trained to generate 25-frame videos using the same-sized context frames and is fine-tuned from SVD Image-to-Video [25 frames]. During fine-tuning, conditions like 6FPS and Motion Bucket Id 127 are fixed to improve output consistency without adjusting hyperparameters.
AI video generation
396.9K
Orthogonal Finetuning (OFT)
The study 'Controlling Text-to-Image Diffusion' explores how to effectively guide or control powerful text-to-image generation models for various downstream tasks. The orthogonal finetuning (OFT) method is proposed, which maintains the model's generative ability. OFT preserves the hypershell energy between neurons, preventing the model from collapsing. The authors consider two important fine-tuning tasks: subject-driven generation and controllable generation. Results show that the OFT method outperforms existing methods in terms of generation quality and convergence speed.
Image Generation
60.4K
3dtopia
3DTopia is a two-stage text-to-3D generation model. In the first stage, a diffusion model quickly generates candidate items. In the second stage, the selected assets from the first stage are optimized. This model can achieve high-quality text-to-3D generation within 5 minutes.
AI 3D tools
113.4K

Make A Shape
Make-A-Shape is a novel 3D generative model designed to efficiently train on massive datasets. It leverages 10 million publicly available shapes. We innovatively introduce a wavelet tree representation, encoding shapes compactly via a subband coefficient filtering scheme. Subband coefficients are then packaged and arranged on a low-resolution mesh to enable diffusion model generation. Furthermore, we propose a subband adaptive training strategy, allowing our model to effectively learn the generation of coarse-to-fine wavelet coefficients. Finally, we extend our framework to be controlled by additional input conditions, enabling shape generation from various modalities, including single/multi-view images, point clouds, and low-resolution voxels. Extensive experiments demonstrate the efficacy of our method in various applications, including unconditional generation, shape completion, and conditional generation. Our approach not only surpasses existing techniques in providing high-quality results but also efficiently generates shapes in seconds, typically requiring only 2 seconds under most conditions.
AI image generation
53.5K
Cogview
CogView is a pre-trained Transformer model designed for general-text-to-image generation. The model consists of 4.1 billion parameters and is capable of generating high-quality and diverse images. The model's training approach follows an abstract-to-specific methodology, first pretraining to acquire general knowledge and then fine-tuning within specific domains to generate images, significantly enhancing the quality of generated images. Notably, the research paper also introduces two techniques to stabilize the training of large models: PB-relax and Sandwich-LN.
AI image generation
67.3K
COMOSVC
COMOSVC is a singing pitch transformation technology based on consistency models that achieves high-quality transformation effects and fast sampling speed. This technology first designs a teacher model based on diffusion for the singing pitch transformation task and then uses self-consistency properties for knowledge distillation to achieve one-step sampling. Compared to the most advanced singing pitch transformation systems based on diffusion, COMOSVC maintains, and even exceeds, comparable transformation performance while significantly faster inference speed.
AI audio editing
80.0K

Generative Powers Of Ten
Generative Powers of Ten is a method for generating multi-scale consistent content using text-to-image models. It enables extreme semantic zoom of a scene, ranging from a wide-angle landscape view of a forest to a macro shot of an insect on a branch. This representation allows us to render continuous zoom videos or interactively explore different scales of a scene. We achieve this through a joint multi-scale diffusion sampling method that encourages consistency across different scales while preserving the integrity of each individual sampling process. Since each generated scale is guided by different text prompts, our method can achieve a deeper level of zoom than traditional super-resolution methods, which may struggle to create new contextual structures at completely different scales. We conducted qualitative comparisons of our method against image super-resolution and external sketching techniques and demonstrated that our method is most effective at generating consistent multi-scale content.
AI Image Generation
51.6K
Ziplora
AI image generation
47.2K

Musenet
MuseNet is a deep neural network model capable of generating 4-minute musical pieces using 10 different instruments. It can blend various musical styles, ranging from country to Mozart and even the Beatles. MuseNet learns and predicts the patterns of harmony, rhythm, and style by analyzing hundreds of thousands of MIDI files, anticipating the next note in each sequence. The model employs the same general unsupervised learning technique used in GPT-2, which predicts the next token in an audio or text sequence.
AI Music Generation
114.8K
Cm3leon By Meta
CM3leon is an advanced model that combines text-to-image and image-to-text generation. It adopts an adaptation-based text model training recipe, including a large-scale retrieval-enhanced pre-training stage and a multi-task supervised fine-tuning stage. CM3leon has similar diversity and effectiveness to autoregressive models, while being cost-effective in training and high-efficient in inference. It is a causal masked mixed-modality (CM3) model that can generate text and image sequences based on any image and text content. Compared to previous models that only perform either text-to-image or image-to-text generation, CM3leon has greater functional extensibility in multi-modal generation.
AI image generation
53.0K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.0K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.4K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
41.7K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
42.8K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.4K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.0K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.1K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M